⚡ Tablers
A blazingly fast PDF table extraction library with python API powered by Rust
![]()



Features#
- 🚀 Blazingly Fast - Core algorithms written in Rust for maximum performance
- 🐍 Pythonic API - Easy-to-use Python interface with full type hints
- 📄 Edge Detection - Accurate table detection using line and rectangle edge analysis
- 📝 Text Extraction - Extract text content from table cells with configurable settings
- 📤 Multiple Export Formats - Export tables to CSV, Markdown, and HTML
- 🔐 Encrypted PDFs - Support for password-protected PDF documents
- 💾 Memory Efficient - Lazy page loading for handling large PDF files
- 🖥️ Cross-Platform - Works on Windows, Linux, and macOS
Why Tablers?#
This project draws significant inspiration from the table extraction modules of pdfplumber and PyMuPDF. Compared to pdfplumber and PyMuPDF, tablers has the following advantages:
- High Performance: Utilizes Rust for high-performance PDF processing
- Higher Accuracy: Tablers optimizes some table detection algorithms to address table extraction problems that other libraries have not fully solved, including:
- Mixed strategies where one is text and the other is lines (#8)
- Tables whose edges are actually narrow closepath polylines (#13)
- Extracting table content when the bottom border is absent (pdfplumber discussion #631)
- Table recognition when outer lines are missing (pdfplumber issue #1296)
- Excluding tables formed by invisible edges (pdfplumber issue #1357)
- More Configurable: Supports customizable table filter settings (
min_rows,min_columns,include_single_cell, e.g., see this issue) - Clean Python Dependencies: No external python dependencies required
Benchmark#
Benchmarked on the ICDAR 2013 Table Competition dataset, evaluating both extraction speed and accuracy across tablers, PyMuPDF, pdfplumber, and camelot. All libraries use their default configuration for table extraction. PyMuPDF excludes tables that have only one row or only one column (see PyMuPDF#3987), and this behaviour is not configurable; among the compared libraries, only tablers allows configuring minimum row/column counts. For a fair comparison, the benchmark therefore includes both tablers (default) and tablers (min 2×2) — the latter with min_rows=2 and min_columns=2 so that single-row/single-column tables are filtered out in the same way as in PyMuPDF. For more on the libraries and settings, see the Libraries compared section in tablers-benchmark.
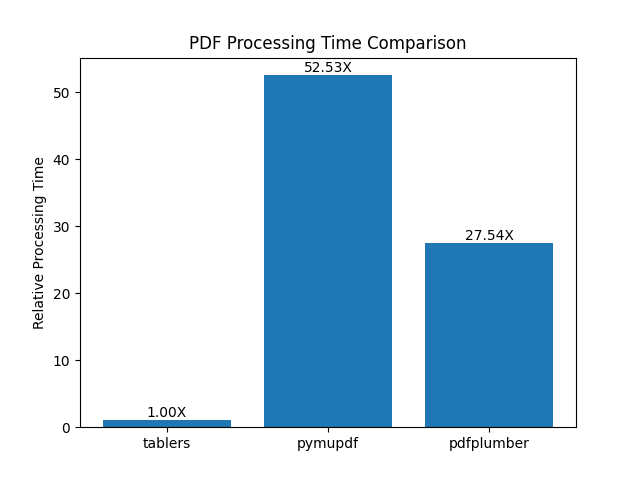
For more details, please refer to the tablers-benchmark repository.
Note#
This solution is primarily designed for text-based PDFs and does not support scanned PDFs.
Installation#
Quick Start#
Basic Table Extraction#
from tablers import Document, find_tables
# Open a PDF document
doc = Document("example.pdf")
# Extract tables from each page
for page in doc.pages():
tables = find_tables(page, extract_text=True)
for table in tables:
print(f"Found table with {len(table.cells)} cells")
for cell in table.cells:
print(f" Cell: {cell.text} at {cell.bbox}")
doc.close()
Using Context Manager#
from tablers import Document, find_tables
with Document("example.pdf") as doc:
page = doc.get_page(0) # Get first page
tables = find_tables(page, extract_text=True)
for table in tables:
print(f"Table bbox: {table.bbox}")
For more advanced usage, please refer to the documents.
Requirements#
- Python >= 3.10
- Supported platforms: Windows (x64), Linux (x64) with glibc >= 2.28, macOS (ARM64)
License#
This project is licensed under the MIT License - see the LICENSE file for details.
Acknowledgments#
- pdfplumber - PDF parsing library
- PyMuPDF - PDF parsing library
- pdfium-render - Rust bindings for PDFium
- PyO3 - Rust bindings for Python